테스트 작업주제: "스프레드시트 뛰어나다 ».
1. 스프레드시트는 다음과 같습니다.
a) 테이블 형태로 구성된 데이터를 저장하고 처리하기 위한 응용 프로그램;
b) 코드 테이블 처리를 위한 응용 프로그램;
c) 장치 개인용 컴퓨터에서 데이터를 처리하는 과정에서 리소스를 관리합니다. 표 형식;
d) 테이블로 작업할 때 개인용 컴퓨터의 자원을 관리하는 시스템 프로그램.
2. 스프레드시트와 일반 스프레드시트의 근본적인 차이점은 다음과 같습니다.
a) 테이블 형식으로 구성된 데이터 처리 가능성
b) 원래 데이터가 변경될 때 공식에 의해 제공된 데이터의 자동 재계산 가능성;
c) 처리된 데이터 간의 관계를 시각화하는 기능
d) 라인에 제시된 데이터를 처리하는 능력 다양한 방식.
3. 스프레드시트 행:
a) 사용자가 임의로 이름을 지정합니다.
b) 러시아 알파벳 A ... Z의 문자로 표시됩니다.
c) 문자로 표시 라틴 알파벳;
d) 번호가 매겨져 있습니다.
4. Excel의 셀 주소는 다음으로 구성됩니다.
가) 파일 이름
b) 주어진 문자 세트;
c) 셀이 위치한 교차점의 열 이름과 행 번호
d) 셀이 위치한 교차점의 행 번호 및 열 이름.
5. Excel에서 셀을 활성화하고 Delete 키를 누르면 다음이 수행됩니다.
a) 셀의 내용이 삭제됩니다.
b) 셀 형식이 지워집니다.
c) 셀이 삭제됩니다.
d) 셀 이름이 삭제됩니다.
6. 표의 정보는 다음 형식으로 표시됩니다.
가) 파일 b) 기록; c) 텍스트, 숫자, 공식.
7. 빠른 데이터 변환 스프레드시트인해 발생합니다...
a) 셀별 정보 배포
b) 데이터를 연결하는 공식의 존재;
c) 빠른 프로세서 작동.
8. Excel의 활성 셀은 다음과 같습니다.
a) 주소가 A1인 셀 b) 프레임으로 표시된 셀; c) 데이터가 입력되는 셀.
9. 스프레드시트 셀 범위를 ...이라고 합니다.
a) 테이블의 모든 채워진 셀 집합
b) 모두의 집합 빈 셀;
c) 직사각형 영역을 형성하는 셀 세트;
d) 영역을 형성하는 셀 집합 자유 형식.
10. 셀 F1에 유효하지 않은 수식 지정
a) =A1+B1*D1; b) =A1+B1/F1; c) =C1.
11. 셀 D1에 쓸 잘못된 수식을 지정하십시오.
a) \u003d 2A 1 + B 2; b) =A1+B2+C3; c) =A1-C3; d) 모든 공식이 허용됩니다.
12. 스프레드시트에서 삭제할 수 없음
가) 라인 b) 열; c) 셀 이름; d) 셀의 내용.
13. 스프레드시트에서 셀 그룹이 선택됩니다.씨 3: 에프 10. 이 그룹에는 몇 개의 세포가 있습니까?
가) 21; b) 24; 다) 28; 라) 32.
14. 표현 , 수학에서 채택된 규칙에 따라 작성된 스프레드시트 형식은 다음과 같습니다.
a) 3*(А1+В1)/(5*(2*В1–3*А2));
b) 3(А1+²1)/5(2²1–3А2);
c) 3* (А1+В1)/ 5* (2* В1–3* А2);
d)3(А1+²1)/(5(2²1–3А2)).
15. 스프레드시트에서 이동하거나 복사하는 경우 절대 링크:
가) 변경하지 마십시오
b) 수식의 새로운 위치에 관계없이 변환됩니다.
c) 공식의 새로운 위치에 따라 변환됩니다.
d) 수식의 길이에 따라 변환됩니다.
16 . 스프레드시트 셀 H5에는 수식 =$B$5*V5가 포함되어 있습니다. 셀 H7에 복사하면 어떤 공식을 얻을 수 있습니까?
a)=$B$7*V7; b)=$B$5*V5; c)=$B$5*V7; d)=B$7*V7.
17. 스프레드시트에서 셀 A1에는 숫자 10이 포함되고 셀 B1에는 수식 =A1/2가 포함되며 C1에는 수식 =SUM(A1:B1)이 포함됩니다. C1의 값은 무엇입니까:
가) 10; b) 15; 2시에; 라) 150.
18. 차트는 다음과 같습니다.
a) 그래픽 표현의 형태 수치, 수치 데이터를 더 쉽게 해석할 수 있도록 합니다.
b) 일정
c) 완성된 표;
19. 막대 차트는 다음과 같습니다.
a) 차트 개별 가치 X 축을 따라 다양한 길이의 줄무늬로 표시됩니다.
b) 개별 값이 데카르트 좌표계의 점으로 표시되는 다이어그램;
c) 개별 값이 다양한 높이의 세로 막대로 표시되는 차트;
d) 하나의 데이터 계열만 허용되는 섹터로 구분된 원으로 표시되는 차트.
20. 히스토그램은 다음에 가장 적합합니다.
a) 분포 표시
b) 비교 다양한 요소여러 떼;
c) 데이터 변경의 역학을 표시합니다.
d) 특정 비율 표시 다양한 징후.
답변:
워드 프로세서 Word에는 생성된 문서에서 다양한 개체를 구현하는 여러 내장 프로그램이 있습니다. 다음을 통해 액세스할 수 있습니다. 삽입/객체.... 가장 인기 있는 두 가지인 차트 빌더와 수식 편집기를 살펴보겠습니다.
다이어그래밍
응용 프로그램은 다이어그램을 작성하는 데 사용됩니다. "마이크로소프트 차트그래프".
차트 작성에 사용되는 데이터가 있는 테이블의 셀을 선택합니다. 콘텐츠 톱 라인선택한 영역의 왼쪽 열은 좌표축의 셰리프 비문에 사용됩니다.
메뉴를 통해 삽입/개체.../만들기"개체 유형" 목록에서 선택 "마이크로소프트 그래프", 그 후에 데이터와 차트가 있는 테이블이 표시됩니다.
테이블에 레이블 설정: 표시되는 테이블의 첫 번째 행의 레이블은 가로 축을 표시하는 데 사용되며 첫 번째 열의 레이블은 범례에 사용됩니다. 범례는 다이어그램 오른쪽에 있는 설명 그림입니다.
차트를 편집합니다. 이렇게 하려면 편집 중인 다이어그램의 요소를 마우스 오른쪽 버튼으로 클릭하면 편집 메뉴가 나타납니다.
차트 외부의 기본 창을 클릭하여 "Microsoft Graph"를 종료합니다.
차트를 문서의 원하는 위치로 이동하고 크기를 조정합니다.
예
수익의 역학 관계를 보여주는 다이어그램을 작성해 보겠습니다(위 표 참조). 이렇게 하려면 테이블에서 간격 A2:F5를 선택하고 "Microsoft Graph"를 로드합니다. 이 범위에는 월 행과 도시 열이 포함됩니다. 가로축과 범례의 레이블에 사용됩니다.
차트를 편집하려면 차트 내부를 마우스 오른쪽 버튼으로 클릭하고 "차트 옵션" 메뉴 항목을 선택합니다. 대부분의 수정을 할 수 있는 "차트 옵션" 창이 열립니다. 예를 들어 가로 축에 레이블을 설정하려면 축 탭을 열고 X 축(범주) 확인란과 자동 확인란을 선택해야 합니다. 차트 유형을 변경하려면 "차트 유형" 메뉴 항목을 선택하십시오.
X축 아래 레이블의 세로 방향을 설정하려면 레이블을 마우스 오른쪽 버튼으로 클릭하고 "축 서식" 메뉴를 선택한 다음 "정렬" 탭에서 세로 방향을 설정합니다.
"Microsoft Graph" 개체가 활성화된 상태에서 메뉴에 액세스하는 경우 데이터/행 형식 열, 테이블 열의 데이터가 X축을 따라 그려집니다.
다이어그램 편집을 위한 모든 작업은 "Microsoft Graph" 작업 중 기본 메뉴를 대체하는 메뉴 모음을 통해 수행할 수 있습니다.
다이어그램 편집의 마지막 단계는 크기를 조정하고 페이지의 올바른 위치에 배치하는 것입니다.
수식 편집기 작업
수식 편집기 "Microsoft Equation"은 설치 시 함께 설치되는 프로그램입니다. 워드 에디터사용자의 요청에 따라. 편집기에는 큰 세트가 있습니다. 수학 기호상당히 복잡한 수식을 나타낼 수 있습니다. 수식을 먼저 인코딩한 다음 특수 프로그램으로 재현하는 TEX 편집기와 달리 "Microsoft Equation"에서는 수식을 작성하는 과정에서 수식을 볼 수 있습니다. 수식을 작성한 후 일반 도면처럼 치수를 변경할 수 있습니다.
수식을 작성하려면 커서를 올바른 위치에 놓고 메뉴에 액세스하십시오. 삽입/개체/Microsoft 수식 3.0. 이 경우 수식을 입력하는 프레임과 두 줄의 버튼이 포함된 수식 편집기 패널이 나타나야 합니다. 버튼의 맨 윗줄은 다음을 정의합니다. 캐릭터 팔레트, 낮추다 - 템플릿 팔레트. 입력 필드 외부를 클릭하여 수식 입력을 완료할 수 있습니다.
수식 입력의 일반적인 순서수식 편집기 패널에서 필요한 요소를 선택하고 표시되는 메뉴에서 수정하는 것입니다. 일반 문자 입력은 지정된 필드의 키보드에서 수행됩니다. 한 필드에서 다른 필드로 이동하거나 새 필드를 입력할 때 커서의 위치와 크기를 모니터링해야 합니다. 예를 들어 커서는 공통분수분자 또는 분모보다 큽니다. 이런 식으로 다음 문자를 입력할 수 있는 위치가 표시됩니다.
공백 삽입수식에서 단순히 해당 키를 눌러 수행할 수 없습니다. 기호 팔레트에서 사용할 수 있는 여러 유형의 공간이 있습니다. 공백을 자주 삽입해야 하는 경우 표에 표시된 키 조합을 사용하는 것이 편리합니다.
수식 정렬예를 들어, 대부분의 경우 수식 편집기 자체가 수식을 작성한 행에 따라 수식을 정렬한다는 사실에도 불구하고 크기를 변경한 후에 필요할 수 있습니다. 수식 전체 또는 일부를 정렬하려면 마우스를 두 번 클릭하여 편집할 수식을 호출하고 정렬할 부분을 선택한 다음 Ctrl 키와 커서 키 중 하나의 조합을 필요한 만큼 여러 번 눌러야 합니다. , 정렬 방향에 따라 다릅니다. 클릭할 때마다 선택한 부분이 1픽셀씩 이동합니다.
제어 질문
- 생성된 문서에서 다양한 개체를 구현하는 내장 프로그램은 어떻게 액세스됩니까?
- 차트를 그리는 데 사용되는 응용 프로그램은 무엇입니까?
- 차트 앱을 선택하는 방법은 무엇입니까?
- 차트를 만드는 방법?
- 차트의 범례는 무엇입니까?
- 가로축 표시 및 범례에 대한 레이블을 설정하는 방법은 무엇입니까?
- 차트를 편집하는 방법?
- 수식 편집기의 기능은 무엇입니까?
- 문서에 수식을 작성하는 방법은 무엇입니까?
- 수식 입력의 일반적인 순서는 무엇입니까?
- 수식에 공백을 삽입하는 방법은 무엇입니까?
- 수식 정렬을 수행하는 방법은 무엇입니까?
이것은 Michael Girvin이라는 책의 한 장입니다. Ctrl+Shift+Enter. Excel에서 배열 수식 마스터하기.
이 메모는 정말 관심이 있는 사람들을 위한 것입니다. 복잡한 공식정렬. 고유한 값 목록을 한 번만 추출하면 된다면 고급 필터나 피벗 테이블을 사용하는 것이 훨씬 쉽습니다. 수식 사용의 주요 이점은 다음과 같습니다. 자동 업데이트소스 데이터 또는 선택 기준을 변경/추가할 때. 읽기 전에 이전 자료에 포함된 아이디어의 기억을 새로 고치는 것이 좋습니다.
- (11장);
- (13장);
- (15장);
- (17장).
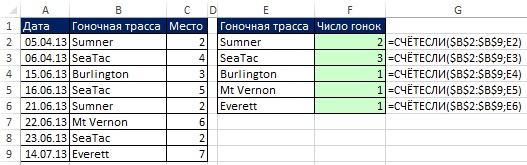
쌀. 19.1. 옵션으로 고유 레코드 추출 고급 필터
노트 또는 형식 다운로드, 형식의 예
옵션을 사용하여 하나의 열에서 고유 목록 추출 고급 필터
무화과에. 19.1은 데이터 세트(범위 A1:C9)를 보여줍니다. 귀하의 목표는 고유한 경마장 목록을 얻는 것입니다. 원본 데이터를 유지해야 하므로 옵션을 사용할 수 없습니다. 중복 제거(메뉴 데이터 –> 작업 데이터 –> 중복 제거). 그러나 당신은 사용할 수 있습니다 고급 필터. 대화 상자를 열려면 고급 필터, 메뉴를 통해 이동 데이터 –> 정렬 및 필터링 –> 추가적으로또는 Alt 키를 누른 상태에서 S, L을 누릅니다(Excel 2007 이상).
열린 대화 상자에서 고급 필터(그림 19.1) 옵션 설정 결과를 다른 위치로 복사, 확인란을 선택하십시오 고유 레코드만, 고유 값을 추출할 영역($B$1:$B$9)과 추출된 데이터가 배치될 첫 번째 셀($E$1)을 지정합니다. 무화과에. 19.2는 결과 고유 목록(범위 E1:E6)을 보여줍니다. 필드 이름을 포함하지 않으면 원래 범위대화 상자 고급 필터(그림 19.1의 $B$2:$B$9 대신) Excel은 범위의 첫 번째 행을 필드 이름으로 취급하므로 중복될 위험이 있습니다. 무화과에. 그림 19.3은 고유 목록의 가능한 많은 용도 중 하나를 보여줍니다.
![]()
옵션을 사용하여 기준에 따라 고유 목록 검색 고급 필터
마지막 예에서는 한 열에서 고유한 목록을 검색했습니다. 고급 필터는 기준을 적용하여 고유한 레코드 세트(즉, 원본 테이블의 전체 행)를 추출할 수도 있습니다. 무화과에. 그림 19.4 및 19.5는 회사 이름이 ABC인 범위 A1:D10에서 고유한 레코드를 추출하려는 상황을 보여줍니다. 이 장의 뒷부분에서 수식을 사용하여 이 작업을 수행하는 방법을 볼 수 있습니다. 그러나 자동 프로세스가 필요하지 않은 경우 다음을 사용할 수 있습니다. 고급 필터, 공식보다 확실히 간단합니다.
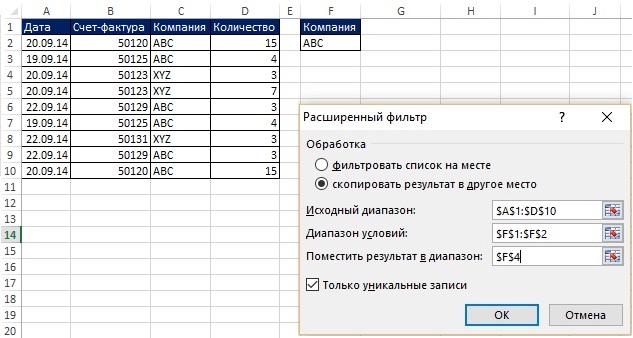
쌀. 19.4. ABC 회사에 대한 고유 항목이 필요합니다. 이미지를 확대하려면 이미지를 마우스 오른쪽 버튼으로 클릭하고 새 탭에서 이미지 열기
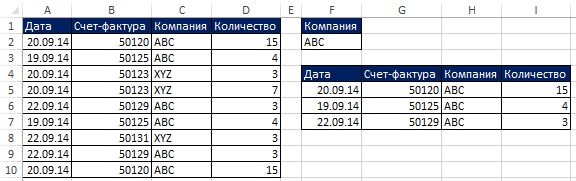
쌀. 19.5. 용법 고급 필터기준에 따라 고유 레코드를 추출하는 것이 수식 방법보다 훨씬 쉽습니다. 그러나 기준 또는 소스 데이터가 변경되면 검색된 레코드가 자동으로 업데이트되지 않습니다.
피벗 테이블을 사용하여 하나의 열에서 고유 목록 추출
이미 피벗 테이블을 사용하고 있다면 피벗 테이블에 필드를 배치할 때마다 문자열또는 열(그림 19.6) 자동으로 고유한 목록을 얻게 됩니다. 무화과에. 그림 19.6은 고유한 경마장 목록을 신속하게 생성한 다음 각 트랙에 대한 방문 수를 계산하는 방법을 보여줍니다. 피벗 테이블은 단일 열에서 고유한 목록을 추출하는 데 유용하지만 기준에 따라 고유한 레코드를 추출하는 데는 유용하지 않을 수 있습니다.
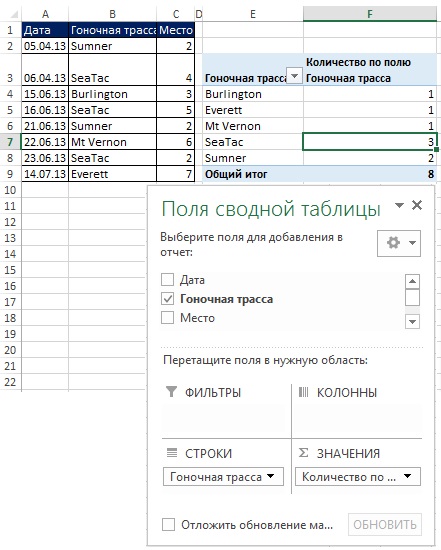
쌀. 19.6. 당신이 사용할 수있는 피벗 테이블고유한 목록과 이를 기반으로 한 후속 계산이 필요한 경우
수식 및 도우미 열을 사용하여 단일 열에서 고유 목록 추출
도우미 열을 사용하면 배열 수식을 사용하는 것보다 고유한 데이터를 검색하기가 더 쉽습니다(그림 19-7). 이 예에서는 (COUNTIF 함수 사용) 및 (도우미 열 사용)에서 배운 메서드를 사용합니다. 이제 B2:B9 범위의 원래 데이터를 변경하면 수식이 D15:D21 영역의 이러한 변경 사항을 자동으로 반영합니다.
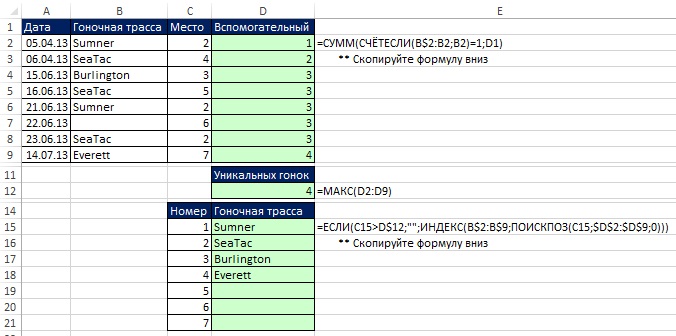
배열 수식: SMALL 함수를 사용하여 하나의 열에서 고유 목록 추출
이 섹션에서 사용된 배열 수식은 이해하기 매우 복잡하기 때문에 생성은 단계로 나뉩니다. 첫 번째는 고유 값을 계산하는 스니펫입니다(17장). 두 번째는 기준 기반 데이터 추출입니다(15장). 무화과에. 그림 19.8은 고유 값을 계산하는 수식을 보여줍니다(이는 배열 수식이므로 Ctrl+Shift+Enter를 눌러 입력합니다). 이 공식의 다음 측면에 주의하십시오.
- FREQUENCY 함수는 숫자 배열을 반환합니다(그림 19.9). 레이스 트랙이 처음 나타나는 경우 원래 데이터에서 발생하는 횟수가 반환됩니다. 각 후속 경마 트랙 발생에 대해 0이 반환됩니다( 참조). 예를 들어 Sumner는 어레이의 첫 번째와 다섯 번째 위치에 나타납니다. 첫 번째 위치에서 FREQUENCY 함수는 2 − 총 수 B2:B9 범위의 여름, 다섯 번째 위치 - 0.
- FREQUENCY 함수는 인수에 배치됩니다. log_expression IF 함수이므로 IF 함수는 null이 아닌 값에 대해 TRUE를 반환하고 0에 대해 FALSE를 반환합니다.
- 논쟁 value_if_true IF 함수는 1을 포함하므로 SUM 함수는 이러한 단위의 수를 계산합니다.
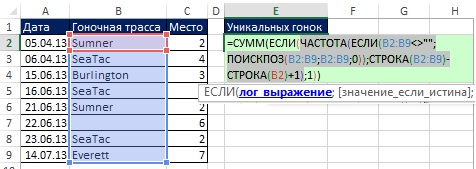
쌀. 19.8. FREQUENCY 함수는 인수에 배치됩니다. log_expression IF 함수
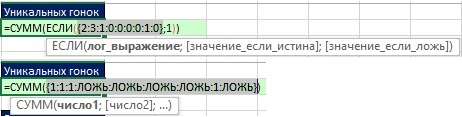
쌀. 19.9. (1) FREQUENCY 함수는 숫자 배열을 반환합니다. (2) IF 함수는 0 이외의 숫자에 대해 1을 반환하고 0에 대해 FALSE를 반환합니다.
이제 고유한 목록을 추출하는 수식을 만들어 보겠습니다. 무화과에. 19.10은 인수에 배치된 상대 위치의 배열을 보여줍니다. 정렬작은 기능.
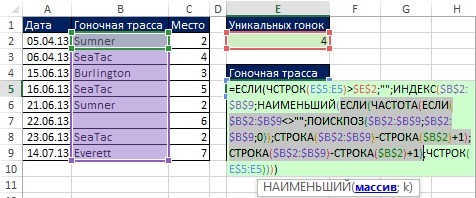
이전 예(그림 19. 9)에서 인수 value_if_true IF 함수는 1을 배치했기 때문에 IF 함수는 1과 FALSE를 반환했습니다. 여기 (그림 19.10) 인수 value_if_true포함: STRING($B$2:$B$9)-ROW($B$2)+1. 따라서 IF 함수(SMALL 함수 내)는 고유한 경주 트랙이 있는 범위의 상대 위치 번호를 반환하거나 중복된 경우 FALSE를 반환합니다(그림 19.11).
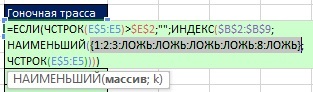
쌀. 19.11. IF 함수는 고유한 레이스 트랙이 있는 범위의 상대 위치 번호를 반환하거나 중복의 경우 FALSE를 반환합니다.
무화과에. 19.12는 공식의 결과를 보여줍니다. 무화과에. 19.13 초기 데이터가 변경되자마자 수식에 이러한 변경 사항이 즉시 반영되는 것을 볼 수 있습니다. 하지만 새 항목을 추가하면 어떻게 될까요? 다음으로 동적 범위 수식을 만드는 방법을 살펴보겠습니다.

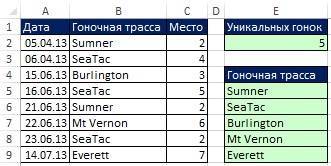
쌀. 19.13. 원본 데이터가 변경되면 수식이 즉시 업데이트됩니다. 필터 및 고급 필터는 VBA 코드를 작성하지 않고 자동으로 업데이트할 수 없습니다.
배열 수식: 동적 범위를 사용하여 하나의 열에서 고유 목록 추출
동적 범위()를 기반으로 특정 이름을 사용하는 수식에 대해 배운 내용으로 마지막 예를 확장해 보겠습니다. 무화과에. 19.14는 이름을 결정하는 공식입니다. 길. 이 수식은 51행 이후에 항목을 입력하지 않는다고 가정합니다.
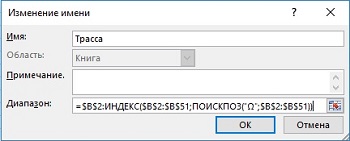
쌀. 19.14. 이름 정의 길수식 기반
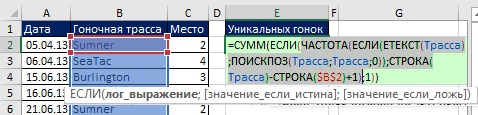
이름을 정의하면 모든 수식에서 사용할 수 있습니다. 무화과에. 그림 19.15는 이름을 사용하여 고유한 값의 수를 세는 방법을 보여줍니다(그림 19.8과 비교). 그리고 그림에서. 그림 19.16은 경주 트랙 목록에서 자체적으로 고유한 값을 추출하는 수식을 보여줍니다. 스니펫 대신 범위<>»»(그림 19.8 및 19.10에서와 같이) ISTEXT 함수가 사용됩니다(모든 텍스트가 TRUE를 반환함). ISTEXT를 사용할 때 B11 셀처럼 숫자를 입력하거나 텍스트가 아닌 다른 값을 입력하면 수식이 해당 값을 무시합니다. 무화과에. 그림 19.17은 수식이 숫자를 무시하고 새 트레이스 이름을 자동으로 추출함을 보여줍니다.
![]()
쌀. 19.16. 추출 고유한 이름동적 범위에 기반한 트레이스
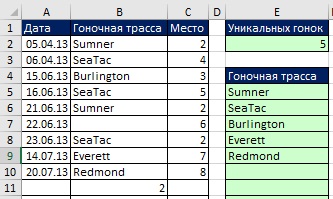
드롭다운 목록에 대한 고유한 값 수식 만들기
방금 고려한 예를 기반으로 두 번째 이름을 정의합니다. 트랙리스트, 또한 동적 범위를 기반으로 하지만 이제 고유 추적 목록을 참조합니다(범위 E5:E14, 그림 19.18). 범위 E5:E14에는 텍스트와 빈 값(길이가 0인 테스트 문자열 - "")만 포함되므로 인수에서 lookup_value MATCH 함수는 와일드카드 *?를 사용할 수 있습니다. (즉, 적어도, 한 문자). 그리고 논쟁에서 match_type MATCH는 값 -1을 사용해야 합니다. 이 값은 적어도 하나의 문자를 포함하는 열에서 텍스트의 마지막 요소를 찾습니다. 그림과 같이. 19.18, 필드에서 특정 이름을 사용할 수 있습니다. 원천창문 입력값 검증(드롭다운 목록 만들기에 대한 자세한 내용은 참조). B열에서 새 데이터가 추가되거나 제거되면 드롭다운 목록이 확장 및 축소될 수 있습니다.
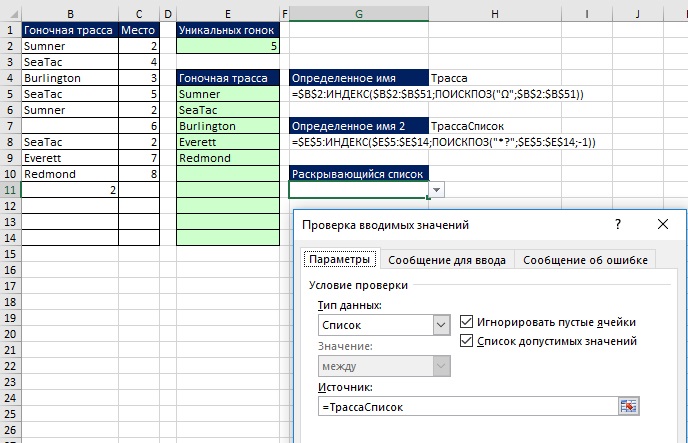
와일드카드를 일반 문자처럼 취급해야 하는 경우
에서 배운 것처럼 때때로 와일드카드를 문자로 취급해야 합니다. 무화과에. 그림 19-18은 이러한 경우에 대한 공식을 수정하는 방법을 보여줍니다. 인수 범위 앞에 물결표를 추가하고 있습니다. lookup_value MATCH 함수를 사용하고 인수의 범위 뒤에 빈 문자열을 추가합니다. lookup_array.
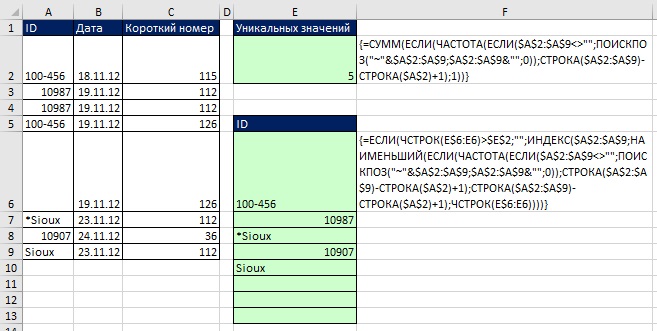
도우미 열 또는 배열 수식을 사용하여 기준에 따라 고유한 레코드 검색
노트의 시작 부분에 기준에 따라 고유한 레코드를 추출하는 것이 좋을 것이라고 표시되었습니다. 고급 필터. 그러나 즉각적인 업데이트가 필요한 경우 도우미 열(그림 19-20) 또는 배열 수식(그림 19-21)을 사용할 수 있습니다.
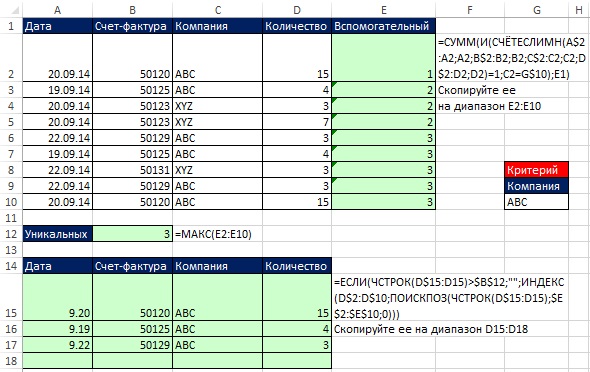
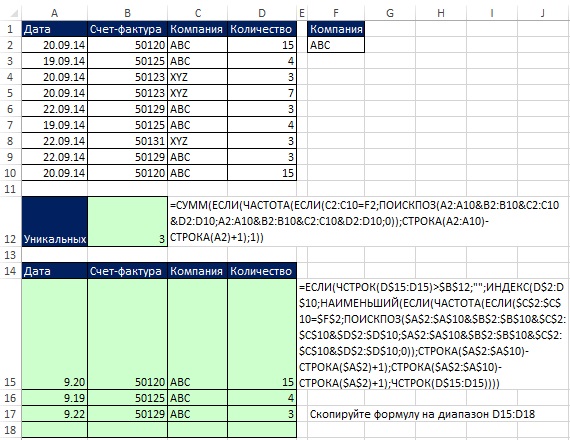
고객 이름 및 판매량을 추출하는 동적 공식
공식은 그림에 나와 있습니다. 19.22. 예를 들어 새 항목을 추가하는 경우 TT트럭라인 17 , 셀 F15의 SUMIF 수식이 자동으로 새 값을 추가합니다. B열에 신규 고객을 추가하면 즉시 E열에 반영되며, F열의 SUMIF 수식이 새로운 합계를 표시합니다.
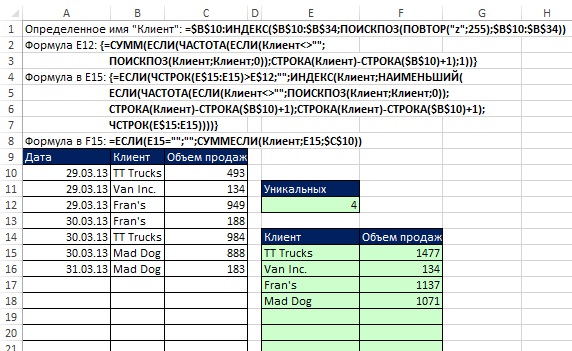
쌀. 19.22. 특정 이름과 두 개의 배열 수식을 사용하여 고유 고객 및 판매량 추출
인수의 SUMIF 함수에 유의하십시오. sum_range하나의 셀 - $C$10을 포함합니다. 다음은 이 주제에 대한 SUIF 수식 도움말의 내용입니다. 인수 sum_range인수와 크기가 다를 수 있습니다. 범위. 합산할 실제 셀을 결정할 때 인수의 왼쪽 위 셀을 시작 셀로 사용 sum_range, 인수의 크기에 해당하는 범위 부분의 셀이 합산됩니다. 범위. 셀 E15 및 F15에 입력된 수식이 열을 따라 복사됩니다.
숫자 값 정렬
숫자를 정렬하는 공식은 매우 간단하지만 혼합 데이터를 정렬하는 경우 엄청나게 복잡합니다. 따라서 즉각적인 업데이트가 필요하지 않은 경우 옵션을 사용하여 수식을 사용하지 않는 것이 좋습니다. 분류. 무화과에. 19.23은 두 가지 정렬 공식을 보여줍니다.
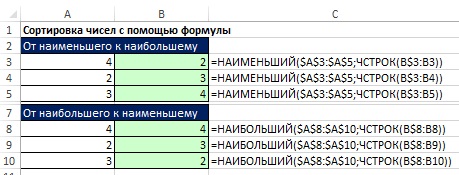
무화과에. 그림 19-24는 도우미 열을 사용하여 숫자를 정렬하는 방법을 보여줍니다. RANK 함수는 같은 숫자를 정렬(동일한 순위 부여)하지 않기 때문에 이들을 구분하기 위해 COUNTIF 함수가 추가되었습니다. COUNTIF 함수에는 한 줄 위로 시작하는 확장된 범위가 있습니다. 이것은 숫자의 첫 번째 항목이 기여하지 않도록 하기 위한 것입니다. 숫자가 두 번째로 나타나면 순위가 1씩 올라갑니다. 이 일련 번호는 INDEX 및 MATCH 함수가 A8:B12 범위에서 레코드를 검색하는 순서를 설정합니다.
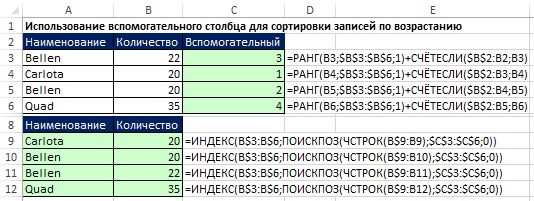
데이터 추출 영역(그림 19.25의 A10:A14 범위)에 보조 컬럼을 생성할 여유가 있다면 SMALL 함수를 기반으로 위에서 설명한 숫자 정렬을 적용하고 이미 이를 기반으로 추출하는 것이 편리하다. 배열 함수를 사용하여 이름을 지정합니다.
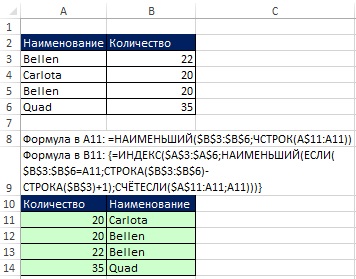
쌀. 19.25. 도우미 열을 사용할 수 없는 경우 SMALL 함수(A11 셀) 및 배열 수식(B11 셀)을 기준으로 정렬을 적용합니다.
종종 비즈니스 및 스포츠에서 N 추출이 필요합니다. 최고의 가치및 해당 값과 관련된 이름입니다. 표시할 레코드 수를 결정하는 COUNTIF 수식(그림 19-26의 셀 A11)으로 솔루션을 시작하십시오. 인수에 유의하십시오. 표준셀 A11의 COUNTIF 함수에서 - 그 이상 D8 셀의 값. 이렇게 하면 모든 테두리 값을 표시할 수 있습니다(이 예에서는 상위 3개를 표시하려고 하지만 적합한 값이 4개 있음).
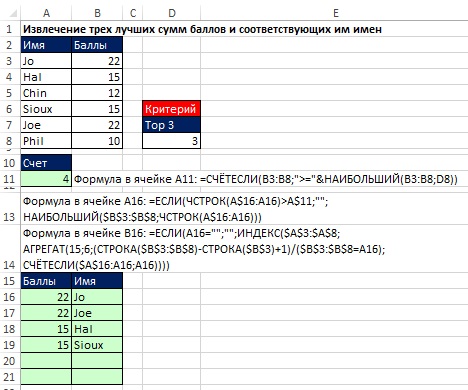
쌀. 19.26. 상위 3개 총점과 해당 이름을 추출합니다. 셀 D8에서 N이 변경되면 A15:B21 영역이 업데이트됩니다.
텍스트 값 정렬
보조 열의 사용이 허용되는 경우 작업이 그리 어렵지 않습니다(그림 19.27). 비교 연산자 핸들 텍스트 기호문자에 할당된 ASCII 숫자 코드를 기반으로 합니다. 셀 C3에서 첫 번째 COUNTIF 함수는 0을 반환하고 두 번째 함수는 1을 더합니다. C4: 2+1, C5: 0+2, C6: 3+1.
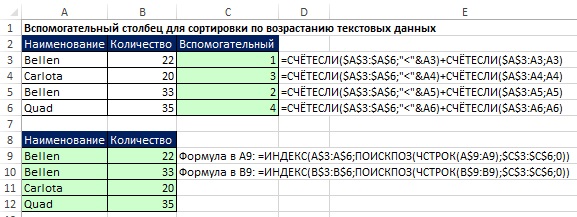
혼합 데이터 정렬
혼합 데이터에서 고유 값을 추출한 다음 정렬하는 공식은 매우 큽니다(그림 19.28). 이 책의 앞부분에서 접한 아이디어를 사용하여 만들어졌습니다. Excel의 표준 정렬 기능이 어떻게 작동하는지 살펴봄으로써 수식 학습을 시작하겠습니다.
Excel에서 결과를 정렬합니다. 다음 순서: 먼저 숫자, 텍스트(길이가 0인 문자열 포함), FALSE, TRUE, 발생 순서대로 오류 값, 빈 셀. 모든 정렬은 ASCII 코드에 따라 발생합니다. 255개의 ASCII 코드가 있으며 각 코드는 1에서 255까지의 숫자에 해당합니다.
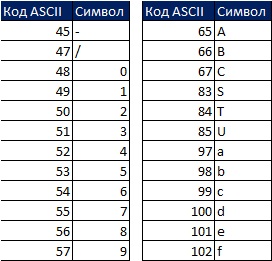
예를 들어 숫자 5는 ASCII 코드 53에 해당하고 문자 S는 ASCII 코드 83에 해당합니다. 5와 S의 두 값을 가장 작은 값에서 가장 큰 값으로 정렬하면 53이 S보다 높기 때문에 5가 S보다 높습니다. 83 미만.
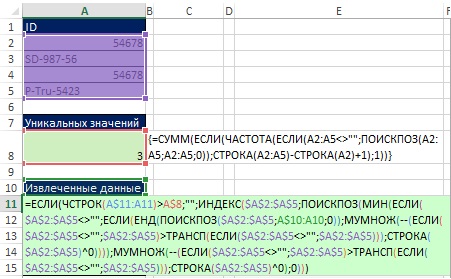
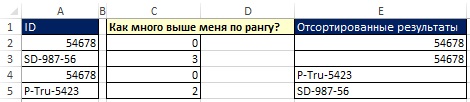
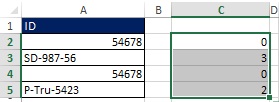
범위 A2:A5(그림 29)의 데이터 세트는 정렬 규칙에 따라 범위 E2:E5로 변환됩니다. 정렬 원칙을 더 잘 이해하려면 C2:C5 범위의 값을 고려하십시오. 예를 들어 "나보다 순위가 몇 위야?"라고 묻는다면 셀 A2(54678)의 ID에 대한 답은 0이 됩니다. 정렬된 목록에서 ID 54678이 맨 위에 있기 때문입니다. SD-987-56 위에 세 개의 ID가 있습니다. C2:C5 범위의 값을 얻으려면 공식이 필요합니다.
먼저 범위 E1:H1을 선택하고 수식 입력줄에 =TRANSP(A2:A5)를 입력하고 Ctrl+Shift+Enter를 눌러 수식을 입력합니다(그림 19.30). 다음으로 수식 입력줄에서 범위 E2:H5를 선택하고 =A2:A5>E1:H1을 입력한 다음 Ctrl+Shift+Enter를 눌러 수식을 입력합니다(그림 19.31). 무화과에. 그림 19.32는 결과 배열의 각 셀에 해당하는 TRUE 및 FALSE 값의 직사각형 배열인 결과를 보여줍니다. "행 머리글이 열 머리글보다 큽니까?"
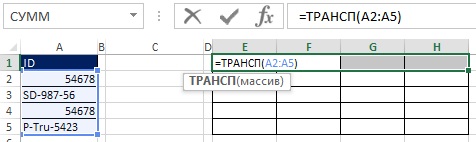
쌀. 19.30. 범위 E1:H1을 선택하고 배열 수식을 입력합니다.
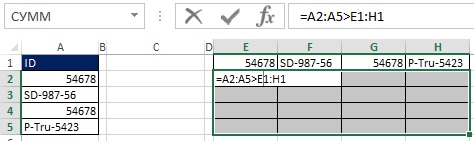
쌀. 19.31. E2:H5 범위에서 배열 수식 입력 =A2:A5>E1:H1
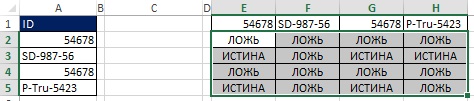
쌀. 19.32. E2:H5 범위의 각 셀에는 "행 머리글이 열 머리글보다 큽니까?"라는 질문에 대한 대답이 포함되어 있습니다.
예를 들어 셀 E3에서 질문은 SD-987-56 > 54678입니다. 54678은 SD-987-56보다 작으므로 답은 TRUE입니다. E3:H3 범위에는 3개의 TRUE 값과 1개의 FALSE 값이 포함됩니다. 무화과를 되돌아 보며. 19.29, 셀 C3에 있는 숫자 3임을 알 수 있습니다.
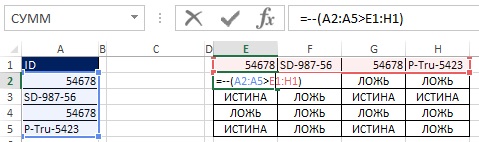
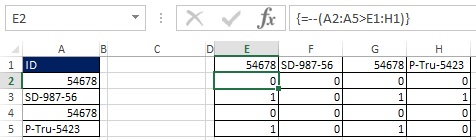
그림 19.33과 19.34에서와 같이 배열 수식에 이중 음수를 추가하여 TRUE와 FALSE 값을 1과 0으로 변환할 수 있습니다. 원래 배열(E2:H5)이 4x4이고 결과를 4x1 배열로 원하기 때문에 MULTIP 기능을 사용합니다(그림 19.35 및 참조). MULTIP 기능은 배열 기능이므로 Ctrl+Shift+Enter를 눌러 입력합니다(그림 19.36). 이제 범위 E2:H5를 사용하는 대신 공식 안에 적절한 요소를 추가합니다(그림 19.37).
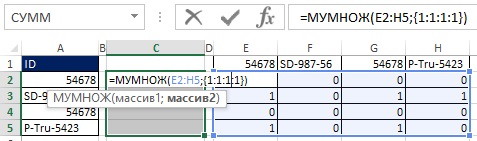
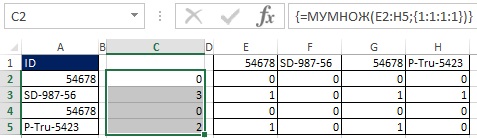
쌀. 19.36. 범위 C2:C5를 선택하고 배열 함수 MMULT를 입력하면 정렬된 목록에서 선택한 ID보다 몇 개의 ID가 더 높은지 나타내는 숫자 열을 얻습니다.
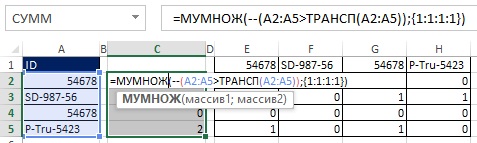
쌀. 19.37. 보조 범위 E2:H5를 사용하는 대신 해당 요소가 수식 내부에 추가됩니다.
무화과에. 그림 19.38은 상수 배열을 ROW($A$2:$A$5)^0으로 바꾸는 방법을 보여줍니다.
쌀. 19.39. 잠재적인 빈 셀을 처리하려면 A2:A5의 모든 발생을 IF(A2:A5로 보완해야 합니다.<>"",A2:A5); STRING 함수는 이러한 추가가 필요하지 않습니다. 함수는 내용이 아닌 셀의 주소로 작동합니다.
최종 공식은 다른 곳에서 사용되므로 모든 범위를 절대값으로 만들어야 합니다(그림 19.40). 무화과에. 19.41은 결과 값을 보여줍니다.
쌀. 19.40. 범위 A2:A5가 절대값으로 변경됨
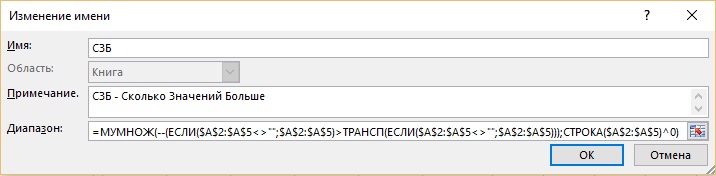
이 요소는 앞으로 두 번 사용되므로 특정 이름으로 저장할 수 있습니다. 대화 상자(그림 19.42)에 표시된 대로 수식에는 MSB - How Many Values Is Greater라는 이름이 지정됩니다.
- 논쟁 정렬 INDEX 함수는 원래 범위 A2:A5를 참조합니다.
- 첫 번째 MATCH 함수는 A2:A5 배열에서 요소의 상대적 위치를 INDEX 함수에 알려줍니다.
- 논쟁하는 동안 lookup_value MATCH 함수는 비워 둡니다.
- 인수의 정의된 이름(SSB) lookup_array값이 0, 2, 마지막으로 3인 요소에 먼저 액세스할 수 있습니다.
- 인수 제로 match_type중복 사용을 제거하는 정확한 일치를 지정합니다.
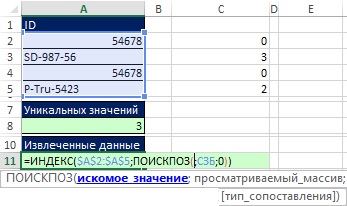
쌀. 19.43. 셀 A11에서 데이터를 추출하고 정렬하는 수식을 시작합니다. 논쟁 lookup_value지금은 MATCH 함수를 비워 둡니다.
인수를 만들기 전에 lookup_value MATCH 기능, 실제로 필요한 것을 기억하십시오. 정렬할 3개의 고유 ID가 있으므로 인수에 3개의 숫자가 필요합니다. lookup_value공식이 복사되기 때문에. 이 숫자를 사용하면 INDEX 함수에 제공하려는 A2:A5 배열의 상대 위치를 찾을 수 있습니다.
- 셀 A11에서 MATCH 함수는 0을 반환하며, 이는 특정 MSB 이름 내 상대 위치 1에 해당합니다.
- 수식이 셀 A12에 복사되면 MATCH 함수는 MSB 내에서 숫자 2와 상대 위치 = 4를 반환해야 합니다.
- 셀 A13에서 MATCH 함수는 3을 반환하고 MSB 내에서 상대 위치 = 2를 반환해야 합니다.
논쟁이 무엇인지 생각할 때 그림이 나타납니다. lookup_value수식을 복사할 때 쿼리는 "아직 사용되지 않은 특정 SSB 이름 내의 최소값을 제공하십시오."와 일치해야 합니다. 그림과 같이. 19.44 수식 요소 MIN(IF(END(MATCH($A$2:$A$5,A$10:A10,0)),MSB))는 수식이 복사될 때 쿼리에 정확히 응답하는 최소값을 반환합니다. 이것이 작동하는 이유는 UND(MATCH($A$2:$A$5,A$10:A10,0)) 스니펫이 두 목록을 비교하기 때문입니다( 참조). 인수에서 확장 범위 A$10:A10에 주목하십시오. lookup_array. 셀 A11에서 UND와 MATCH의 조합은 SSB에서 모든 고유 번호를 추출하여 MIN 함수에 제공하는 데 도움이 됩니다. 수식을 셀 A12로 복사하면 셀 A11에서 추출된 ID가 다시 확장된 범위에 있고 다시 $A$2:$A$5 범위에서 찾을 수 있습니다. 그러나 YEND는 FALSE를 반환하고 MSB에서 값 0이 추출되지 않은 것을 확인하려면 Ctrl+Shift+Enter를 눌러 그림 19.44의 배열 수식을 입력한 후 복사하십시오.
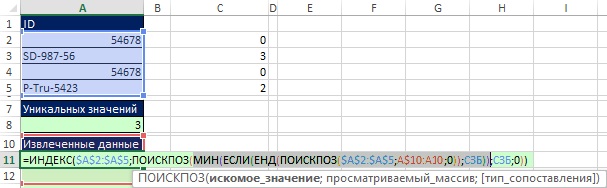
쌀. 19.44. 인수의 수식 요소 lookup_value MATCH 함수는 "아직 사용되지 않은 특정 MSB 이름 내의 최소값 제공" 쿼리와 일치합니다.
무화과에. 19.45는 인수에서 lookup_array두 번째 함수 MATCH에서 A$10:A10 범위가 A$10:A11로 확장되었습니다. 이 공식이 어떻게 작동하는지 이해하려면 조각을 하나씩 선택하고 F9를 클릭하십시오(그림 19.46–19.49).
쌀. 19.45. 이제 확장 가능한 범위 A$10:A11(셀 A12)에 첫 번째 ID(54678)가 포함됩니다.
쌀. 19.46. UND 함수와 두 번째 MATCH의 조합은 부울 값의 배열을 제공합니다. 두 개의 FALSE 값은 특정 MSB 이름에서 null 값을 제외합니다.
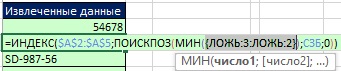
쌀. 19.47. 0은 제거되고 숫자 3과 2만 남습니다. 숫자 2가 최소이므로 다음에 추출해야 합니다.
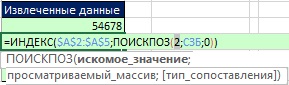
쌀. 19.48. MIN 함수는 숫자 2를 선택합니다. 이제 MATCH 함수는 INDEX 함수의 올바른 상대 위치를 찾을 수 있습니다.
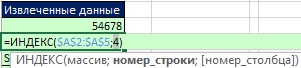
쌀. 19.49. INDEX 함수는 A2:A5 범위에서 ID의 상대적 네 번째 위치에 해당하는 값 2를 검색합니다.
이제 셀 A11로 돌아가서 빈 셀이 수식에 영향을 주지 않도록 다른 조건을 추가할 수 있습니다(그림 19.50).
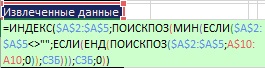
쌀. 19.50. MIN 함수 내부에는 두 가지 조건이 있습니다. 첫 번째: "셀이 비어 있습니까?", 두 번째: "값이 아직 사용되지 않았습니까?"
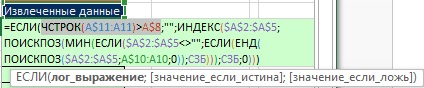
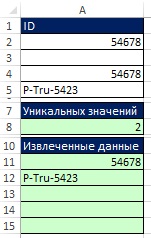
무화과에. 19.51은 최종 공식을 보여줍니다. 정렬된 고유 값을 가져온 후 A11:A15 범위의 행이 비어 있도록 조건을 추가했습니다. 무화과에. 19.52는 셀 A3이 비워지면 어떻게 되는지 보여줍니다. 빈 셀을 확인하는 추가 기능이 작동했습니다.
쉽지 않았습니다. 하지만 여기까지 읽으셨다면 즐거우셨기를 바랍니다.